5. Conclusion and Recommendation
Contents
5. Conclusion and Recommendation¶
In this project, we set out to create a tool to quantify the risk of the endpoints of each API based on security and data sovereignty markers. To this end, the team has been successful in creating a model that is not only highly interpretable. More importantly, it scores highly in the acceptance criteria (Recall) - attaining a recall score of 0.99 for both the train and test set.
Despite the team’s success, we decided to further investigate the validity of the risk labels. To re-emphasise, API security is a completely novel field and thus there is no absolute or ground truth to their labels. As such, we attempted an unsupervised learning technique.
5.1 Unsupervised Learning¶
Currently, risk labeling is subject to the capstone partner’s expertise. However, data can be clustered in many ways, and there exist a large body of algorithms designed to reveal underlying patterns.
We have built a visual analytics tool using Factor analysis of mixed data (FAMD) and Tensorflow Embedding Projector 5 that helps analyze the similarity between the data points. As seen in Fig. 7, we have found that the data points were not distinct in the 3D plane, indicating that the risk labels might not be sufficiently reliable.
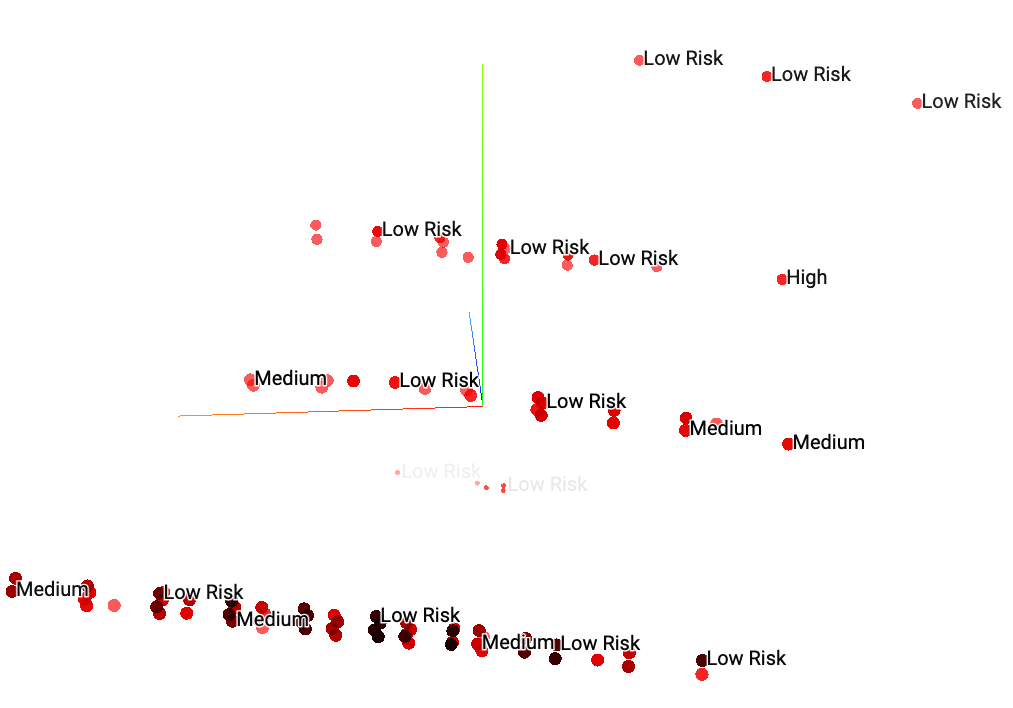
Fig. 7 PCA Visualization of Current Risk Label showing no distinct clusters between low and medium risk labels¶
Using K-prototypes clustering algorithm, the team attempted to group similar data points according to their metadata. Visually, this algorithm provides more distinguishable clusters that are more equally distributed with clear boundaries (See Fig. 8 below). We can also inspect all the attributes of each data point and compare the similarity within the intra-cluster and inter-cluster boundary (See Fig. 9 below).
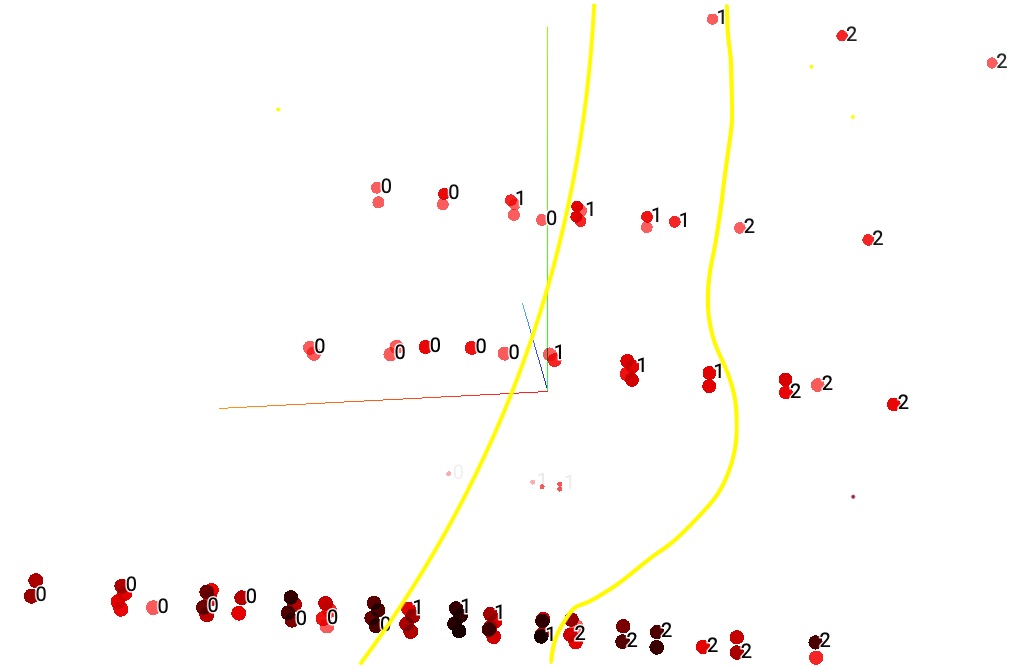
Fig. 8 PCA Visualization of Cluster Label showing three distinct clusters along the vertical axis¶
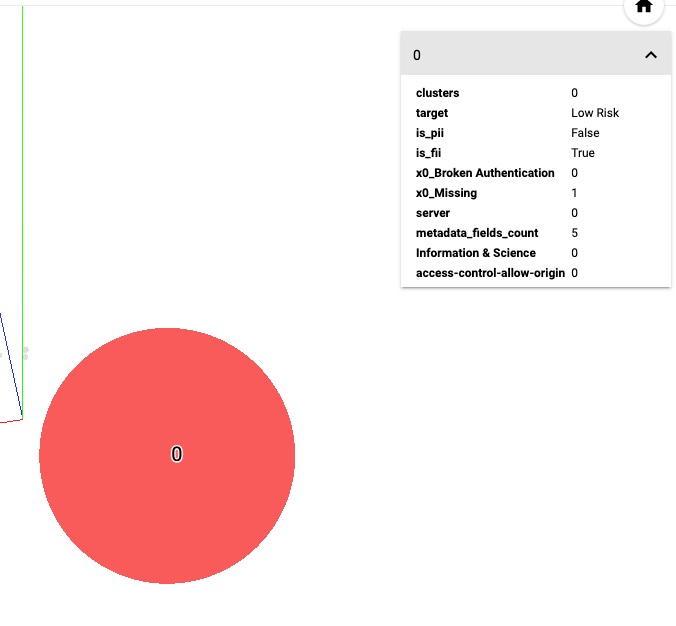
Fig. 9 PCA Visualization of Cluster Label with metadata¶
In conclusion, our team is highly satisfied with the data product that we will be handing over to TeejLab. While we are aware that some improvements are required before deployment, the team has been most proud of extracting hidden features, quantifying the value of categorical features, and highlighting areas of improvement where our partner has overlooked. This is ultimately a small step in the right direction in this uncharted domain.